hot100图论题解
200. 岛屿数量
问题描述
给你一个由 '1'(陆地)和 '0'(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。
示例 1:
1
2
3
4
5
6
7
输入:grid = [
["1","1","1","1","0"],
["1","1","0","1","0"],
["1","1","0","0","0"],
["0","0","0","0","0"]
]
输出:1
示例 2:
1
2
3
4
5
6
7
输入:grid = [
["1","1","0","0","0"],
["1","1","0","0","0"],
["0","0","1","0","0"],
["0","0","0","1","1"]
]
输出:3
提示:
m == grid.lengthn == grid[i].length1 <= m, n <= 300grid[i][j]的值为'0'或'1'
题解
要解决这个问题,可以使用深度优先搜索(DFS)或广度优先搜索(BFS)来遍历网格,并将已访问过的陆地标记为已访问。以下是使用 C++ 的详细解法。
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
#include <vector>
#include <queue>
using namespace std;
class Solution {
public:
void dfs(vector<vector<char>>& grid, int i, int j) {
// 判断边界条件
if (i < 0 || i >= grid.size() || j < 0 || j >= grid[0].size() || grid[i][j] == '0') {
return;
}
// 将当前格子标记为已访问
grid[i][j] = '0';
// 上、下、左、右四个方向继续递归
dfs(grid, i - 1, j); // 上
dfs(grid, i + 1, j); // 下
dfs(grid, i, j - 1); // 左
dfs(grid, i, j + 1); // 右
}
int numIslands(vector<vector<char>>& grid) {
int m = grid.size();
int n = grid[0].size();
int count = 0; // 记录岛屿数量
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
// 如果当前格子是陆地,开始 DFS
if (grid[i][j] == '1') {
++count; // 岛屿数量加 1
dfs(grid, i, j); // 把当前岛屿的所有陆地都标记为已访问
}
}
}
return count;
}
};
思路解析
- 遍历整个网格:
- 对于每个格子,如果值为
'1'(表示陆地),则表明找到了一块新的岛屿。 - 每次发现一个岛屿时,将岛屿计数器
count加 1。
- 对于每个格子,如果值为
- DFS 标记岛屿:
- 当遇到陆地时,通过 DFS 遍历当前岛屿的所有连通部分,并将这些部分标记为
'0',以避免重复访问。
- 当遇到陆地时,通过 DFS 遍历当前岛屿的所有连通部分,并将这些部分标记为
- 四个方向搜索:
- 从当前格子出发,向上、下、左、右递归搜索,确保所有相连的陆地都被标记。
复杂度分析
- 时间复杂度:
- 每个格子最多被访问一次,因此时间复杂度为 $O(m \times n)$,其中 $m$ 和 $n$ 分别是网格的行数和列数。
- 空间复杂度:
- DFS 的递归调用栈空间为 $O(m \times n)$(最坏情况下整个网格都是陆地)。
BFS 解法
如果不想用递归,也可以用队列实现 BFS:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
class Solution {
public:
void bfs(vector<vector<char>>& grid, int i, int j) {
int m = grid.size();
int n = grid[0].size();
queue<pair<int, int>> q;
q.push({i, j});
grid[i][j] = '0';
while (!q.empty()) {
auto [x, y] = q.front();
q.pop();
// 上、下、左、右四个方向
vector<pair<int, int>> directions = {{-1, 0}, {1, 0}, {0, -1}, {0, 1}};
for (auto [dx, dy] : directions) {
int nx = x + dx, ny = y + dy;
if (nx >= 0 && nx < m && ny >= 0 && ny < n && grid[nx][ny] == '1') {
grid[nx][ny] = '0'; // 标记为已访问
q.push({nx, ny});
}
}
}
}
int numIslands(vector<vector<char>>& grid) {
int m = grid.size();
int n = grid[0].size();
int count = 0;
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
if (grid[i][j] == '1') {
++count;
bfs(grid, i, j);
}
}
}
return count;
}
};
示例运行
对于输入:
1
2
3
4
5
6
7
8
9
vector<vector<char>> grid = {
{'1', '1', '1', '1', '0'},
{'1', '1', '0', '1', '0'},
{'1', '1', '0', '0', '0'},
{'0', '0', '0', '0', '0'}
};
Solution sol;
int result = sol.numIslands(grid);
输出:
1
result == 1
对于第二个示例,输出 result == 3。
994. 腐烂的橘子
问题描述
在给定的 m x n 网格 grid 中,每个单元格可以有以下三个值之一:
- 值
0代表空单元格; - 值
1代表新鲜橘子; - 值
2代表腐烂的橘子。
每分钟,腐烂的橘子 周围 4 个方向上相邻 的新鲜橘子都会腐烂。
返回 直到单元格中没有新鲜橘子为止所必须经过的最小分钟数。如果不可能,返回 -1 。
示例 1:
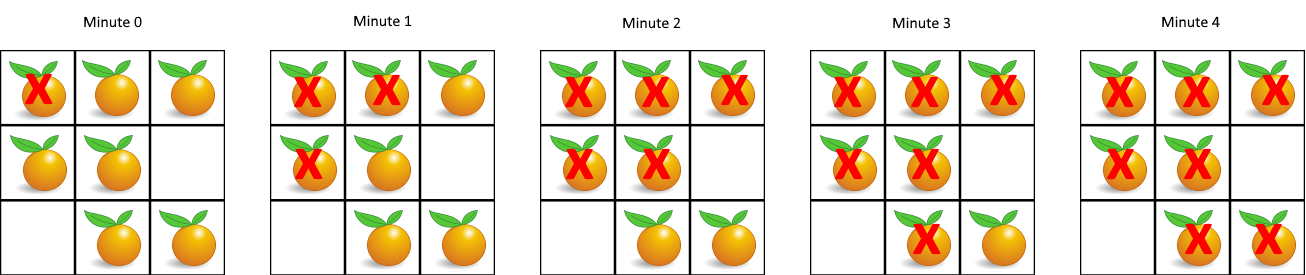
1
2
输入:grid = [[2,1,1],[1,1,0],[0,1,1]]
输出:4
示例 2:
1
2
3
输入:grid = [[2,1,1],[0,1,1],[1,0,1]]
输出:-1
解释:左下角的橘子(第 2 行, 第 0 列)永远不会腐烂,因为腐烂只会发生在 4 个方向上。
示例 3:
1
2
3
输入:grid = [[0,2]]
输出:0
解释:因为 0 分钟时已经没有新鲜橘子了,所以答案就是 0 。
提示:
m == grid.lengthn == grid[i].length1 <= m, n <= 10grid[i][j]仅为0、1或2
题解
这道题是经典的 多源广度优先搜索(BFS) 问题,可以使用队列模拟腐烂扩散的过程。以下是详细的解法和代码实现。
解决思路
- 初始化队列:
- 首先遍历整个网格,将所有的腐烂橘子(值为
2)的位置加入队列,并记录新鲜橘子的数量fresh_count。
- 首先遍历整个网格,将所有的腐烂橘子(值为
- BFS 模拟腐烂过程:
- 从队列中取出腐烂橘子的位置,尝试将其上下左右四个方向的新鲜橘子腐烂,并将这些橘子加入队列,同时减少
fresh_count。
- 从队列中取出腐烂橘子的位置,尝试将其上下左右四个方向的新鲜橘子腐烂,并将这些橘子加入队列,同时减少
- 记录分钟数:
- 每一轮腐烂传播完成后,增加计时器
minutes,直到队列为空。
- 每一轮腐烂传播完成后,增加计时器
- 判断结果:
- 如果所有新鲜橘子都腐烂了,返回分钟数
minutes。 - 如果仍有新鲜橘子无法腐烂,返回
-1。
- 如果所有新鲜橘子都腐烂了,返回分钟数
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
#include <vector>
#include <queue>
using namespace std;
class Solution {
public:
int orangesRotting(vector<vector<int>>& grid) {
int m = grid.size();
int n = grid[0].size();
queue<pair<int, int>> q; // 队列存储腐烂橘子的坐标
int fresh_count = 0; // 新鲜橘子的数量
int minutes = 0; // 计时器
// 初始化队列和新鲜橘子数量
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
if (grid[i][j] == 2) {
q.push({i, j});
} else if (grid[i][j] == 1) {
++fresh_count;
}
}
}
// 如果没有新鲜橘子,直接返回 0
if (fresh_count == 0) return 0;
// 四个方向
vector<pair<int, int>> directions = {{-1, 0}, {1, 0}, {0, -1}, {0, 1}};
// BFS 开始传播腐烂
while (!q.empty()) {
int size = q.size();
bool spread = false; // 本轮是否传播
for (int i = 0; i < size; ++i) {
auto [x, y] = q.front();
q.pop();
// 扩散到上下左右
for (auto [dx, dy] : directions) {
int nx = x + dx, ny = y + dy;
if (nx >= 0 && nx < m && ny >= 0 && ny < n && grid[nx][ny] == 1) {
grid[nx][ny] = 2; // 标记为腐烂
q.push({nx, ny});
--fresh_count; // 新鲜橘子数量减少
spread = true;
}
}
}
// 如果本轮有传播,增加分钟数
if (spread) ++minutes;
}
// 如果还有未腐烂的新鲜橘子,返回 -1
return fresh_count == 0 ? minutes : -1;
}
};
思路解析
- 多源 BFS:
- 初始化时,将所有腐烂橘子作为 BFS 的起点。
- 每轮 BFS 扩散一次,向四个方向感染新鲜橘子。
- 终止条件:
- 队列为空时停止 BFS。
- 如果在 BFS 结束后还有新鲜橘子(
fresh_count > 0),说明这些橘子无法被感染。
- 特例处理:
- 如果网格中一开始就没有新鲜橘子,直接返回
0。
- 如果网格中一开始就没有新鲜橘子,直接返回
复杂度分析
- 时间复杂度:
- 每个橘子最多被访问一次,因此时间复杂度为 $O(m \times n)$,其中 $m$ 和 $n$ 分别是网格的行数和列数。
- 空间复杂度:
- BFS 队列最多存储所有腐烂橘子的坐标,空间复杂度为 $O(m \times n)$。
示例运行
输入:
1
2
3
4
5
6
7
8
vector<vector<int>> grid = {
{2, 1, 1},
{1, 1, 0},
{0, 1, 1}
};
Solution sol;
int result = sol.orangesRotting(grid);
输出:
1
result == 4
总结
- 本解法使用 BFS 模拟腐烂过程,直观高效。
- 可扩展性强,可以处理更大的网格问题。
- 特殊情况下,如没有新鲜橘子或无法腐烂的橘子,代码能够正确返回结果。
207. 课程表
问题描述
你这个学期必须选修 numCourses 门课程,记为 0 到 numCourses - 1 。
在选修某些课程之前需要一些先修课程。 先修课程按数组 prerequisites 给出,其中 prerequisites[i] = [ai, bi] ,表示如果要学习课程 ai 则 必须 先学习课程 bi 。
- 例如,先修课程对
[0, 1]表示:想要学习课程0,你需要先完成课程1。
请你判断是否可能完成所有课程的学习?如果可以,返回 true ;否则,返回 false 。
示例 1:
1
2
3
输入:numCourses = 2, prerequisites = [[1,0]]
输出:true
解释:总共有 2 门课程。学习课程 1 之前,你需要完成课程 0 。这是可能的。
示例 2:
1
2
3
输入:numCourses = 2, prerequisites = [[1,0],[0,1]]
输出:false
解释:总共有 2 门课程。学习课程 1 之前,你需要先完成课程 0 ;并且学习课程 0 之前,你还应先完成课程 1 。这是不可能的。
提示:
1 <= numCourses <= 20000 <= prerequisites.length <= 5000prerequisites[i].length == 20 <= ai, bi < numCoursesprerequisites[i]中的所有课程对 互不相同
题解
这道题属于典型的 有向图检测环 问题,可以用两种方法解决:
- 拓扑排序(Kahn’s Algorithm 或 BFS)
- 深度优先搜索(DFS)
只要检测到有环存在,就无法完成课程学习。
解法 1:拓扑排序(BFS)
通过入度数组 inDegree 和队列进行拓扑排序。如果能够遍历所有课程,则说明没有环。
算法步骤
- 构建有向图:
- 使用邻接表
graph表示课程之间的依赖关系。 - 使用数组
inDegree存储每门课程的入度(依赖其他课程的数量)。
- 使用邻接表
- 初始化队列:
- 将所有入度为
0的课程加入队列(这些课程没有前置依赖,可以直接开始学习)。
- 将所有入度为
- BFS 遍历:
- 从队列中取出课程,将其对应的出边(依赖它的课程)的入度减一。
- 如果某课程的入度变为
0,将其加入队列。
- 检查结果:
- 如果能够完成所有课程(即遍历的课程数等于总课程数),返回
true。 - 否则返回
false。
- 如果能够完成所有课程(即遍历的课程数等于总课程数),返回
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
#include <vector>
#include <queue>
using namespace std;
class Solution {
public:
bool canFinish(int numCourses, vector<vector<int>>& prerequisites) {
vector<vector<int>> graph(numCourses); // 邻接表
vector<int> inDegree(numCourses, 0); // 入度数组
// 构建图和入度数组
for (auto& pre : prerequisites) {
graph[pre[1]].push_back(pre[0]);
++inDegree[pre[0]];
}
// 初始化队列,将所有入度为 0 的课程入队
queue<int> q;
for (int i = 0; i < numCourses; ++i) {
if (inDegree[i] == 0) {
q.push(i);
}
}
// 拓扑排序
int count = 0; // 记录已完成的课程数量
while (!q.empty()) {
int course = q.front();
q.pop();
++count;
// 遍历当前课程的邻接节点
for (int nextCourse : graph[course]) {
--inDegree[nextCourse];
if (inDegree[nextCourse] == 0) {
q.push(nextCourse);
}
}
}
// 如果完成的课程数等于总课程数,则可以完成所有课程
return count == numCourses;
}
};
解法 2:深度优先搜索(DFS)
使用 DFS 检测有向图中的环。
算法步骤
- 构建有向图:
- 使用邻接表
graph表示课程之间的依赖关系。
- 使用邻接表
- 定义状态数组:
0: 未访问。1: 正在访问(当前路径)。2: 已访问(不在当前路径)。
- DFS 检测环:
- 如果在同一条路径中再次访问到某课程(即状态为
1),则说明存在环。 - 遍历所有课程,检测是否可以完成。
- 如果在同一条路径中再次访问到某课程(即状态为
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
#include <vector>
using namespace std;
class Solution {
public:
bool dfs(int course, vector<vector<int>>& graph, vector<int>& visited) {
if (visited[course] == 1) return false; // 检测到环
if (visited[course] == 2) return true; // 已访问过,无需重复检查
visited[course] = 1; // 标记为正在访问
for (int nextCourse : graph[course]) {
if (!dfs(nextCourse, graph, visited)) {
return false;
}
}
visited[course] = 2; // 标记为已访问
return true;
}
bool canFinish(int numCourses, vector<vector<int>>& prerequisites) {
vector<vector<int>> graph(numCourses); // 邻接表
vector<int> visited(numCourses, 0); // 访问状态数组
// 构建图
for (auto& pre : prerequisites) {
graph[pre[1]].push_back(pre[0]);
}
// 遍历所有课程,检查是否有环
for (int i = 0; i < numCourses; ++i) {
if (!dfs(i, graph, visited)) {
return false;
}
}
return true;
}
};
复杂度分析
拓扑排序(BFS)
- 时间复杂度:$O(V + E)$,其中 $V$ 是课程数,$E$ 是先修课程数。
- 空间复杂度:$O(V + E)$,用于存储图和队列。
深度优先搜索(DFS)
- 时间复杂度:$O(V + E)$,遍历每个节点和每条边。
- 空间复杂度:$O(V + E)$,存储图和递归栈。
示例运行
输入:
1
2
3
4
5
int numCourses = 2;
vector<vector<int>> prerequisites = {{1, 0}};
Solution sol;
bool result = sol.canFinish(numCourses, prerequisites);
输出:
1
result == true
总结
- 拓扑排序 更适合大规模的课程表,因为它直观且非递归。
- DFS 则更适合需要显式检测环的场景,但递归可能会导致栈溢出。
208. 实现 Trie (前缀树)
问题描述
Trie(发音类似 “try”)或者说 前缀树 是一种树形数据结构,用于高效地存储和检索字符串数据集中的键。这一数据结构有相当多的应用情景,例如自动补全和拼写检查。
请你实现 Trie 类:
Trie()初始化前缀树对象。void insert(String word)向前缀树中插入字符串word。boolean search(String word)如果字符串word在前缀树中,返回true(即,在检索之前已经插入);否则,返回false。boolean startsWith(String prefix)如果之前已经插入的字符串word的前缀之一为prefix,返回true;否则,返回false。
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
输入
["Trie", "insert", "search", "search", "startsWith", "insert", "search"]
[[], ["apple"], ["apple"], ["app"], ["app"], ["app"], ["app"]]
输出
[null, null, true, false, true, null, true]
解释
Trie trie = new Trie();
trie.insert("apple");
trie.search("apple"); // 返回 True
trie.search("app"); // 返回 False
trie.startsWith("app"); // 返回 True
trie.insert("app");
trie.search("app"); // 返回 True
提示:
1 <= word.length, prefix.length <= 2000word和prefix仅由小写英文字母组成insert、search和startsWith调用次数 总计 不超过 $3 * 10^4$ 次
题解
前缀树(Trie)是一种用于高效字符串存储和查询的数据结构,通常用于实现字符串前缀查询功能,例如自动补全和拼写检查。
实现思路
- 节点定义:
- 每个节点存储一个子节点数组
children,用于表示当前字符的下一个可能字符。 - 一个布尔值
isEnd,表示从根节点到当前节点的路径是否构成一个完整的单词。
- 每个节点存储一个子节点数组
- 核心操作:
insert: 按字符逐层插入,每层创建不存在的节点。search: 按字符逐层查找,最后检查是否到达一个完整单词的终止节点。startsWith: 按字符逐层查找,只需判断前缀是否存在。
- 空间优化:
- 使用固定大小的数组(假设字符范围为小写字母 ‘a’-‘z’),以减少哈希表的开销。
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
#include <string>
#include <vector>
using namespace std;
class Trie {
private:
struct TrieNode {
vector<TrieNode*> children; // 子节点数组
bool isEnd; // 是否是单词结尾
TrieNode() : children(26, nullptr), isEnd(false) {}
};
TrieNode* root;
public:
Trie() {
root = new TrieNode(); // 初始化根节点
}
void insert(string word) {
TrieNode* node = root;
for (char ch : word) {
int index = ch - 'a';
if (!node->children[index]) {
node->children[index] = new TrieNode();
}
node = node->children[index];
}
node->isEnd = true; // 标记为单词结尾
}
bool search(string word) {
TrieNode* node = root;
for (char ch : word) {
int index = ch - 'a';
if (!node->children[index]) {
return false; // 找不到单词
}
node = node->children[index];
}
return node->isEnd; // 检查是否是完整单词
}
bool startsWith(string prefix) {
TrieNode* node = root;
for (char ch : prefix) {
int index = ch - 'a';
if (!node->children[index]) {
return false; // 前缀不存在
}
node = node->children[index];
}
return true; // 前缀存在
}
};
测试示例
1
2
3
4
5
6
7
8
9
10
11
12
int main() {
Trie trie;
trie.insert("apple");
cout << trie.search("apple") << endl; // 输出: 1 (true)
cout << trie.search("app") << endl; // 输出: 0 (false)
cout << trie.startsWith("app") << endl; // 输出: 1 (true)
trie.insert("app");
cout << trie.search("app") << endl; // 输出: 1 (true)
return 0;
}
复杂度分析
- 时间复杂度:
insert: $O(L)$,其中 $L$ 是插入单词的长度。search: $O(L)$,其中 $L$ 是查询单词的长度。startsWith: $O(L)$,其中 $L$ 是查询前缀的长度。
- 空间复杂度:
- 每个节点需要存储 26 个子节点指针和一个布尔值。
- 在最坏情况下(所有可能单词都插入),总节点数为 $O(L \times N)$,其中 $L$ 是单词平均长度,$N$ 是单词数。
优点和改进
- 优点:
- 插入和查询效率高。
- 支持快速的前缀查找。
- 改进:
- 使用压缩路径(如 Radix Trie 或 Patricia Trie)进一步优化空间。
- 如果字符范围较大(如 Unicode 字符),可以用哈希表代替固定大小的数组来存储子节点。
通过以上实现,我们可以高效地插入、查询和前缀匹配,非常适合大规模字符串操作场景。