hot100回溯题解
46. 全排列
问题描述
给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。
示例 1:
1
2
输入:nums = [1,2,3]
输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
示例 2:
1
2
输入:nums = [0,1]
输出:[[0,1],[1,0]]
示例 3:
1
2
输入:nums = [1]
输出:[[1]]
提示:
1 <= nums.length <= 6-10 <= nums[i] <= 10nums中的所有整数 互不相同
题解
本题要求生成给定数组的所有全排列,是一个经典的回溯问题。
解法:回溯法
回溯法通过构建递归树,逐步生成排列。每次选择一个未使用的数字加入当前排列,并继续递归,直到排列完成。
算法步骤
- 选择与撤销:
- 每次从未使用的数字中选择一个加入当前排列。
- 在递归返回后撤销选择,恢复到上一个状态。
- 终止条件:
- 当前排列长度等于数组长度时,记录结果。
- 剪枝优化:
- 使用一个布尔数组
used标记当前数字是否已被选择,避免重复。
- 使用一个布尔数组
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
#include <vector>
using namespace std;
class Solution {
public:
vector<vector<int>> permute(vector<int>& nums) {
vector<vector<int>> result; // 存储所有排列结果
vector<int> current; // 当前排列
vector<bool> used(nums.size(), false); // 标记数字是否已使用
backtrack(nums, used, current, result);
return result;
}
private:
void backtrack(vector<int>& nums, vector<bool>& used, vector<int>& current, vector<vector<int>>& result) {
// 终止条件:当前排列长度等于数组长度
if (current.size() == nums.size()) {
result.push_back(current); // 保存当前排列
return;
}
// 遍历每个数字
for (int i = 0; i < nums.size(); ++i) {
if (used[i]) continue; // 如果数字已使用,跳过
// 做选择
used[i] = true;
current.push_back(nums[i]);
// 递归
backtrack(nums, used, current, result);
// 撤销选择
used[i] = false;
current.pop_back();
}
}
};
复杂度分析
- 时间复杂度:
- 全排列有 $n!$ 种可能,每种排列需要 $O(n)$ 时间构造。
- 总时间复杂度为 O$(n \times n!)$。
- 空间复杂度:
- 递归栈深度为 $O(n)$。
- 需要 $O(n)$ 额外空间存储布尔数组
used和当前排列current。 - 总空间复杂度为 $O(n)$。
示例运行
输入:
1
2
3
vector<int> nums = {1, 2, 3};
Solution sol;
vector<vector<int>> result = sol.permute(nums);
输出:
1
2
3
4
5
6
7
8
// result == [
// [1, 2, 3],
// [1, 3, 2],
// [2, 1, 3],
// [2, 3, 1],
// [3, 1, 2],
// [3, 2, 1]
// ]
改进:优化递归
若希望减少空间消耗,可直接通过交换数组元素来生成全排列,无需额外的布尔数组。
交换法代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
class Solution {
public:
vector<vector<int>> permute(vector<int>& nums) {
vector<vector<int>> result;
backtrack(nums, 0, result);
return result;
}
private:
void backtrack(vector<int>& nums, int start, vector<vector<int>>& result) {
// 终止条件
if (start == nums.size()) {
result.push_back(nums);
return;
}
// 遍历从 `start` 到末尾的所有数字
for (int i = start; i < nums.size(); ++i) {
swap(nums[start], nums[i]); // 交换当前数字
backtrack(nums, start + 1, result); // 递归
swap(nums[start], nums[i]); // 撤销交换
}
}
};
复杂度分析(交换法)
- 时间复杂度:
- 同样为 $O(n \times n!)$。
- 空间复杂度:
- 递归栈深度为 $O(n)$,无需额外数组,空间复杂度优化为 $O(n)$。
总结
- 回溯法 是生成全排列的标准方法,通过选择和撤销的递归方式构建解。
- 交换法 是回溯的一种优化,避免了布尔数组的使用,更加简洁。
- 对于数组长度较短的问题(如本题最多 6 个数字),两种方法的性能差异不大。
78. 子集
问题描述
给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。
示例 1:
1
2
输入:nums = [1,2,3]
输出:[[],[1],[2],[1,2],[3],[1,3],[2,3],[1,2,3]]
示例 2:
1
2
输入:nums = [0]
输出:[[],[0]]
提示:
1 <= nums.length <= 10-10 <= nums[i] <= 10nums中的所有元素 互不相同
题解
本题要求生成一个数组的所有子集,是一个经典的回溯问题,也可以用迭代法或位运算来解决。
解法 1:回溯法
回溯法通过构建递归树逐步生成子集。每个元素可以选择加入子集或不加入,从而形成所有可能的子集。
算法步骤
- 选择与递归:
- 每个元素有两个选择:加入当前子集或不加入。
- 递归地构建剩余元素的子集。
- 终止条件:
- 当前索引超出数组范围时,保存当前子集。
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#include <vector>
using namespace std;
class Solution {
public:
vector<vector<int>> subsets(vector<int>& nums) {
vector<vector<int>> result; // 存储所有子集
vector<int> current; // 当前子集
backtrack(nums, 0, current, result);
return result;
}
private:
void backtrack(vector<int>& nums, int start, vector<int>& current, vector<vector<int>>& result) {
// 保存当前子集
result.push_back(current);
// 遍历从 `start` 开始的所有元素
for (int i = start; i < nums.size(); ++i) {
// 选择当前元素
current.push_back(nums[i]);
// 递归生成剩余子集
backtrack(nums, i + 1, current, result);
// 撤销选择
current.pop_back();
}
}
};
解法 2:迭代法
每次向已有子集中加入一个新元素,生成新的子集。
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
class Solution {
public:
vector<vector<int>> subsets(vector<int>& nums) {
vector<vector<int>> result = ;
for (int num : nums) {
int size = result.size();
for (int i = 0; i < size; ++i) {
vector<int> newSubset = result[i];
newSubset.push_back(num);
result.push_back(newSubset);
}
}
return result;
}
};
解法 3:位运算法
一个数组的所有子集可以用二进制数表示:数组长度为 $n$,则 $2^n$ 个子集对应 0 到 $2^n-1$ 的二进制数。
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
class Solution {
public:
vector<vector<int>> subsets(vector<int>& nums) {
int n = nums.size();
int totalSubsets = 1 << n; // 2^n
vector<vector<int>> result;
for (int mask = 0; mask < totalSubsets; ++mask) {
vector<int> subset;
for (int i = 0; i < n; ++i) {
if (mask & (1 << i)) { // 检查第 i 位是否为 1
subset.push_back(nums[i]);
}
}
result.push_back(subset);
}
return result;
}
};
复杂度分析
回溯法
- 时间复杂度:$O(n \cdot 2^n)$,其中 $2^n$ 是子集的数量,$n$ 是每个子集的平均长度。
- 空间复杂度:$O(n)$,递归栈的深度。
迭代法
- 时间复杂度:$O(n \cdot 2^n)$,每次迭代生成新的子集。
- 空间复杂度:$O(2^n)$,存储所有子集。
位运算法
- 时间复杂度:$O(n \cdot 2^n)$,每个子集生成需要 $O(n)$ 时间。
- 空间复杂度:$O(2^n)$,存储所有子集。
示例运行
输入:
1
2
3
vector<int> nums = {1, 2, 3};
Solution sol;
vector<vector<int>> result = sol.subsets(nums);
输出:
1
2
3
4
5
6
7
8
9
10
// result == [
// [],
// [1],
// [2],
// [1, 2],
// [3],
// [1, 3],
// [2, 3],
// [1, 2, 3]
// ]
总结
- 回溯法 是生成子集的标准方法,代码直观易懂。
- 迭代法 简洁高效,直接通过逐步扩展子集生成结果。
- 位运算法 利用二进制特性实现,适合于较小规模的问题。
17. 电话号码的字母结合
问题描述
给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。答案可以按 任意顺序 返回。
给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。

示例 1:
1
2
输入:digits = "23"
输出:["ad","ae","af","bd","be","bf","cd","ce","cf"]
示例 2:
1
2
输入:digits = ""
输出:[]
示例 3:
1
2
输入:digits = "2"
输出:["a","b","c"]
提示:
0 <= digits.length <= 4digits[i]是范围['2', '9']的一个数字。
题解
本题是一个典型的回溯问题,核心在于将数字映射到字母,并逐步构建所有可能的字母组合。
解法:回溯法
- 数字到字母的映射:
- 建立一个映射表,将数字
2-9映射到对应的字母集合。
- 建立一个映射表,将数字
- 回溯生成组合:
- 从第一个数字开始,依次选择一个字母加入当前组合,递归处理剩余数字。
- 当当前组合的长度等于输入字符串长度时,将其加入结果集。
- 终止条件:
- 当处理完所有数字时,递归结束。
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
#include <vector>
#include <string>
using namespace std;
class Solution {
public:
vector<string> letterCombinations(string digits) {
if (digits.empty()) return {}; // 如果输入为空,返回空结果集
// 数字到字母的映射表
vector<string> mapping = {
"", // 0
"", // 1
"abc", // 2
"def", // 3
"ghi", // 4
"jkl", // 5
"mno", // 6
"pqrs", // 7
"tuv", // 8
"wxyz" // 9
};
vector<string> result; // 存储所有组合结果
string current; // 当前的字母组合
backtrack(digits, 0, mapping, current, result);
return result;
}
private:
void backtrack(const string& digits, int index, const vector<string>& mapping, string& current, vector<string>& result) {
// 如果当前组合长度等于输入数字长度,加入结果集
if (index == digits.size()) {
result.push_back(current);
return;
}
// 获取当前数字对应的字母集合
string letters = mapping[digits[index] - '0'];
for (char letter : letters) {
// 选择当前字母
current.push_back(letter);
// 递归处理下一个数字
backtrack(digits, index + 1, mapping, current, result);
// 撤销选择
current.pop_back();
}
}
};
复杂度分析
- 时间复杂度:
- 假设输入字符串的长度为 $n$,每个数字对应的字母集合最多有 4 个字母。
- 全部组合数量最多为 $4^n$。
- 每次递归的操作复杂度为 $O(n)$。
- 总时间复杂度为 $O(n \cdot 4^n)$。
- 空间复杂度:
- 递归栈的深度为 $O(n)$。
- 额外空间存储当前组合字符串和映射表,复杂度为 $O(n)$。
示例运行
输入:
1
2
3
string digits = "23";
Solution sol;
vector<string> result = sol.letterCombinations(digits);
输出:
1
// result == ["ad", "ae", "af", "bd", "be", "bf", "cd", "ce", "cf"]
优化与扩展
- 迭代法:
- 用迭代代替递归,逐步构建组合,但实现复杂性较高。
- 处理空输入:
- 在开始时检查输入字符串是否为空,直接返回空结果集,避免不必要的递归。
总结
- 回溯法是解决本题的标准方法,代码清晰直观。
- 由于输入长度有限,算法的时间复杂度在实际运行中是可以接受的。
- 可以扩展到支持更复杂的字符集或自定义的数字到字母映射场景。
39. 组合总和
问题描述
给你一个 无重复元素 的整数数组 candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数 target 的 所有 不同组合 ,并以列表形式返回。你可以按 任意顺序 返回这些组合。
candidates 中的 同一个 数字可以 无限制重复被选取 。如果至少一个数字的被选数量不同,则两种组合是不同的。
对于给定的输入,保证和为 target 的不同组合数少于 150 个。
示例 1:
1
2
3
4
5
6
输入:candidates = [2,3,6,7], target = 7
输出:[[2,2,3],[7]]
解释:
2 和 3 可以形成一组候选,2 + 2 + 3 = 7 。注意 2 可以使用多次。
7 也是一个候选, 7 = 7 。
仅有这两种组合。
示例 2:
1
2
输入: candidates = [2,3,5], target = 8
输出: [[2,2,2,2],[2,3,3],[3,5]]
示例 3:
1
2
输入: candidates = [2], target = 1
输出: []
提示:
1 <= candidates.length <= 302 <= candidates[i] <= 40candidates的所有元素 互不相同1 <= target <= 40
题解
本题是一个典型的回溯问题,通过构建递归树找到所有可能的组合,使其元素和等于目标值 target。与其他回溯问题不同的是,这里允许重复使用同一个元素。
解法:回溯法
算法思路
- 选择与递归:
- 每次选择一个候选数加入当前组合。
- 递归计算目标值减去该数后的子问题。
- 如果目标值变为 0,说明当前组合是一个有效解,保存结果。
- 剪枝优化:
- 如果当前目标值小于 0,直接结束递归。
- 每次递归时,限制可选的候选数为当前或之后的数,避免重复组合。
- 终止条件:
- 当前目标值为 0 时,记录当前组合。
- 当前目标值小于 0 时,结束递归。
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
#include <vector>
using namespace std;
class Solution {
public:
vector<vector<int>> combinationSum(vector<int>& candidates, int target) {
vector<vector<int>> result; // 存储所有组合
vector<int> current; // 当前组合
backtrack(candidates, target, 0, current, result);
return result;
}
private:
void backtrack(vector<int>& candidates, int target, int start, vector<int>& current, vector<vector<int>>& result) {
// 如果目标值为 0,记录当前组合
if (target == 0) {
result.push_back(current);
return;
}
// 遍历候选数
for (int i = start; i < candidates.size(); ++i) {
// 剪枝:如果当前数大于目标值,跳过
if (candidates[i] > target) continue;
// 选择当前数
current.push_back(candidates[i]);
// 递归:允许重复使用当前数,因此下一次递归的起点仍为 i
backtrack(candidates, target - candidates[i], i, current, result);
// 撤销选择
current.pop_back();
}
}
};
复杂度分析
- 时间复杂度:
- 假设数组大小为 $n$,目标值为 $T$,每个数可以被选多次。
- 递归树的深度为 $T$,每层最多遍历 $n$ 个候选数。
- 总的时间复杂度约为 $O(n^{T})$。
- 空间复杂度:
- 递归栈深度为 $O(T)$。
- 存储当前组合
current的额外空间为 $O(T)$。 - 总空间复杂度为 $O(T)$。
示例运行
输入:
1
2
3
4
vector<int> candidates = {2, 3, 6, 7};
int target = 7;
Solution sol;
vector<vector<int>> result = sol.combinationSum(candidates, target);
输出:
1
// result == [[2, 2, 3], [7]]
优化与扩展
- 剪枝优化:
- 预先对
candidates进行排序,递归中可以提前剪枝:如果当前候选数大于目标值,直接结束循环。
- 预先对
- 结果去重:
- 本题中每个数可以被重复使用,因此无需特别处理重复问题。
- 若不允许重复,则可以通过跳过已使用的数来避免重复组合。
总结
- 本题的关键在于如何通过回溯构建递归树,并通过剪枝优化减少不必要的计算。
- 对于目标值较小的情况(如本题目标值最多为 40),回溯法能够高效找到所有解。
22. 括号生成
问题描述
数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。
示例 1:
1
2
输入:n = 3
输出:["((()))","(()())","(())()","()(())","()()()"]
示例 2:
1
2
输入:n = 1
输出:["()"]
提示:
1 <= n <= 8
题解
本题是一个经典的 回溯问题,需要通过递归生成所有可能的括号组合,并确保括号是有效的。
解法:回溯法
算法思路
- 括号有效性:
- 在任意时刻,左括号
(的数量不能超过给定对数 $n$。 - 在任意时刻,右括号
)的数量不能超过左括号的数量。
- 在任意时刻,左括号
- 递归过程:
- 从空字符串开始,每次选择添加一个左括号
(或右括号)。 - 终止条件是左右括号的数量都达到 $n$ 时,将当前字符串加入结果集。
- 从空字符串开始,每次选择添加一个左括号
- 剪枝:
- 如果左括号数量已经达到 $n$,不能再添加左括号。
- 如果右括号数量等于左括号数量,不能再添加右括号。
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
#include <vector>
#include <string>
using namespace std;
class Solution {
public:
vector<string> generateParenthesis(int n) {
vector<string> result;
string current;
backtrack(result, current, 0, 0, n);
return result;
}
private:
void backtrack(vector<string>& result, string& current, int open, int close, int max) {
// 如果当前字符串长度等于 2 * n,保存结果
if (current.length() == max * 2) {
result.push_back(current);
return;
}
// 尝试添加左括号
if (open < max) {
current.push_back('(');
backtrack(result, current, open + 1, close, max);
current.pop_back(); // 撤销选择
}
// 尝试添加右括号
if (close < open) {
current.push_back(')');
backtrack(result, current, open, close + 1, max);
current.pop_back(); // 撤销选择
}
}
};
复杂度分析
- 时间复杂度:
- 生成的有效括号组合的数量为第 $n$ 个 卡塔兰数 $C_n = \frac{1}{n+1} \binom{2n}{n}$。
- 每个组合的生成时间为 $O(n)$,因此总时间复杂度为 $O(4^n / \sqrt{n})$。
- 空间复杂度:
- 递归栈的深度为 $O(n)$,当前字符串
current的存储需要 $O(n)$。 - 总空间复杂度为 $O(n)$。
- 递归栈的深度为 $O(n)$,当前字符串
示例运行
输入:
1
2
3
int n = 3;
Solution sol;
vector<string> result = sol.generateParenthesis(n);
输出:
1
// result == ["((()))", "(()())", "(())()", "()(())", "()()()"]
优化与扩展
- 动态规划:
- 通过递推生成括号组合,可以减少回溯中的无效路径。
- $dp[i]$ 表示生成 $i$ 对括号的所有有效组合。
- 状态转移方程: $dp[i] = \sum_{j=0}^{i-1} \text{dp[j]} \times \text{dp[i-1-j]}$
- 字典序生成:
- 按字典序生成括号组合,适合场景:当组合的顺序有明确要求。
总结
- 回溯法是解决括号生成问题的经典方法,适合直观的递归场景。
- 对于较大的 $n$,回溯法性能优异,且代码简单清晰。
- 动态规划可以进一步优化生成过程,但实现相对复杂。
79. 单词搜索
问题描述
给定一个 m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。
示例 1:

1
2
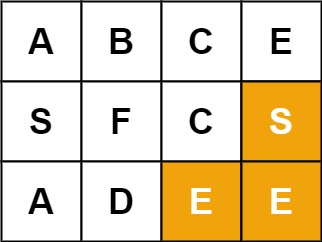
输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "ABCCED"
输出:true
示例 2:
1
2
输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "SEE"
输出:true
示例 3:

1
2
输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "ABCB"
输出:false
提示:
m == board.lengthn = board[i].length1 <= m, n <= 61 <= word.length <= 15board和word仅由大小写英文字母组成
进阶:你可以使用搜索剪枝的技术来优化解决方案,使其在 board 更大的情况下可以更快解决问题?
题解
本题是一个典型的 回溯问题,需要在二维网格中寻找目标单词的路径,关键在于如何处理路径约束和剪枝。
解法:回溯法
算法思路
- 核心逻辑:
- 从网格中的每个点出发,尝试构造目标单词
word。 - 对于当前字符,递归尝试从其相邻的四个方向扩展。
- 使用一个标记(如临时修改网格或额外的布尔数组)避免重复使用同一个单元格。
- 从网格中的每个点出发,尝试构造目标单词
- 终止条件:
- 当前字符不匹配,返回
false。 - 已经找到完整单词,返回
true。
- 当前字符不匹配,返回
- 剪枝:
- 如果当前位置字符不匹配,直接终止当前路径的探索。
- 通过修改原网格来标记已访问节点,减少空间复杂度。
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
#include <vector>
#include <string>
using namespace std;
class Solution {
public:
bool exist(vector<vector<char>>& board, string word) {
int m = board.size(), n = board[0].size();
// 遍历网格中的每个点作为起点
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
// 如果找到单词,返回 true
if (backtrack(board, word, i, j, 0)) {
return true;
}
}
}
return false; // 如果所有路径都失败,返回 false
}
private:
bool backtrack(vector<vector<char>>& board, const string& word, int i, int j, int index) {
// 终止条件:当前字符匹配完成
if (index == word.size()) return true;
// 越界或字符不匹配
if (i < 0 || i >= board.size() || j < 0 || j >= board[0].size() || board[i][j] != word[index]) {
return false;
}
// 临时标记当前节点已访问
char temp = board[i][j];
board[i][j] = '#';
// 四个方向探索
bool found = backtrack(board, word, i - 1, j, index + 1) || // 上
backtrack(board, word, i + 1, j, index + 1) || // 下
backtrack(board, word, i, j - 1, index + 1) || // 左
backtrack(board, word, i, j + 1, index + 1); // 右
// 恢复当前节点
board[i][j] = temp;
return found;
}
};
复杂度分析
- 时间复杂度:
- 假设网格大小为 $m \times n$,单词长度为 $k$。
- 最多需要遍历网格中的每个点,每个点最多进行 $4^k$ 次递归。
- 时间复杂度为 $O(m \times n \times 4^k)$,但由于剪枝,实际复杂度会小于这个值。
- 空间复杂度:
- 使用递归栈的深度为 $O(k)$,其中 $k$ 为单词的长度。
- 修改网格作为标记,避免额外空间开销。
示例运行
输入:
1
2
3
4
5
6
7
8
vector<vector<char>> board = {
{'A', 'B', 'C', 'E'},
{'S', 'F', 'C', 'S'},
{'A', 'D', 'E', 'E'}
};
string word = "ABCCED";
Solution sol;
bool result = sol.exist(board, word);
输出:
1
// result == true
进阶优化
- 剪枝优化:
- 提前判断当前路径是否可能构造单词,例如当剩余路径长度不足时直接终止递归。
- 双向搜索:
- 如果单词很长,可以尝试从两个方向(起点和终点)同时搜索以缩小搜索空间。
- Trie 优化:
- 如果需要同时查找多个单词(如变种题目),可以将所有单词存储到 Trie 中,然后在网格中搜索单词时复用 Trie 进行剪枝。
总结
- 回溯是解决此类二维搜索问题的经典方法。
- 通过剪枝和标记访问,可以有效减少冗余搜索。
- 面对更大规模问题,可以结合 Trie 等数据结构进一步优化性能。
131. 分割回文串
问题描述
给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是 回文串 。返回 s 所有可能的分割方案。
示例 1:
1
2
输入:s = "aab"
输出:[["a","a","b"],["aa","b"]]
示例 2:
1
2
输入:s = "a"
输出:[["a"]]
提示:
1 <= s.length <= 16s仅由小写英文字母组成
题解
本题是一个 回溯问题,需要生成所有可能的分割方案,并验证每个子串是否为回文串。为了加速回文串验证,可以预处理回文信息。
解法:回溯法 + 动态规划预处理
算法思路
预处理回文信息:
使用一个二维数组
isPalindrome,表示子串s[i...j]是否为回文。使用动态规划填充
isPalindrome数组:$\text{isPalindrome}[i][j] = (s[i] == s[j]) \land (\text{j - i <= 2 或 isPalindrome}[i+1][j-1])$
回溯构建分割方案:
- 从字符串的起点开始尝试分割。
- 每次选择一个子串,如果该子串是回文,则递归处理剩余部分。
- 如果到达字符串末尾,记录当前分割方案。
剪枝优化:
- 使用预处理结果快速判断子串是否为回文,避免重复计算。
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
#include <vector>
#include <string>
using namespace std;
class Solution {
public:
vector<vector<string>> partition(string s) {
int n = s.size();
vector<vector<bool>> isPalindrome(n, vector<bool>(n, false));
vector<vector<string>> result;
vector<string> current;
// 预处理回文信息
for (int i = n - 1; i >= 0; --i) {
for (int j = i; j < n; ++j) {
if (s[i] == s[j] && (j - i <= 2 || isPalindrome[i + 1][j - 1])) {
isPalindrome[i][j] = true;
}
}
}
// 回溯寻找所有分割方案
backtrack(s, 0, isPalindrome, current, result);
return result;
}
private:
void backtrack(const string& s, int start, const vector<vector<bool>>& isPalindrome,
vector<string>& current, vector<vector<string>>& result) {
if (start == s.size()) {
result.push_back(current); // 分割到末尾,保存结果
return;
}
for (int end = start; end < s.size(); ++end) {
if (isPalindrome[start][end]) { // 如果子串是回文
current.push_back(s.substr(start, end - start + 1)); // 选择当前子串
backtrack(s, end + 1, isPalindrome, current, result); // 递归处理剩余部分
current.pop_back(); // 撤销选择
}
}
}
};
复杂度分析
- 时间复杂度:
- 预处理回文:需要填充 $n \times n$ 的
isPalindrome数组,时间复杂度为 $O(n^2)$。 - 回溯分割:每个字符最多被访问一次,分割的方案数量为卡塔兰数 $C_n$,因此回溯部分复杂度为 $O(n \cdot 2^n)$。
- 总时间复杂度为 $O(n^2 + n \cdot 2^n)$。
- 预处理回文:需要填充 $n \times n$ 的
- 空间复杂度:
isPalindrome数组占用 $O(n^2)$ 空间。- 回溯过程中递归栈和当前路径占用 $O(n)$ 空间。
- 总空间复杂度为 $O(n^2)$。
示例运行
输入:
1
2
3
string s = "aab";
Solution sol;
vector<vector<string>> result = sol.partition(s);
输出:
1
// result == [["a", "a", "b"], ["aa", "b"]]
优化与扩展
- 空间优化:
- 可以用一维数组替代二维数组来存储回文信息,节省空间。
- 多次查询场景:
- 如果需要多次查询不同字符串的分割方案,可以将回文信息存储到哈希表中,避免重复计算。
总结
- 本题的关键是 快速验证回文性 和 回溯分割字符串。
- 动态规划预处理回文信息可以显著加速计算。
- 适合处理长度较短的字符串,因其复杂度主要受递归方案数量影响。
51. N 皇后
问题描述
按照国际象棋的规则,皇后可以攻击与之处在同一行或同一列或同一斜线上的棋子。
n 皇后问题 研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。
给你一个整数 n ,返回所有不同的 n 皇后问题 的解决方案。
每一种解法包含一个不同的 n 皇后问题 的棋子放置方案,该方案中 'Q' 和 '.' 分别代表了皇后和空位。
示例 1:

1
2
3
输入:n = 4
输出:[[".Q..","...Q","Q...","..Q."],["..Q.","Q...","...Q",".Q.."]]
解释:如上图所示,4 皇后问题存在两个不同的解法。
示例 2:
1
2
输入:n = 1
输出:[["Q"]]
提示:
1 <= n <= 9
题解
本题要求在 $n \times n$ 的棋盘上放置 $n$ 个皇后,使得任何两个皇后都不能在同一行、同一列或同一斜线上。解决此问题的经典方法是使用 回溯法。
解法:回溯法
算法思路
- 逐行放置皇后:
- 从第 0 行开始,每次尝试在当前行的每一列放置皇后,判断该位置是否有效。
- 如果有效,则递归尝试放置下一行的皇后。
- 判断有效性:
- 一个皇后的位置需要满足:
- 不在同一列。
- 不在同一主对角线:$row - col$ 值相等。
- 不在同一副对角线:$row + col$ 值相等。
- 一个皇后的位置需要满足:
- 回溯:
- 如果无法在某行找到合法位置,回溯到上一行,尝试下一个位置。
- 记录结果:
- 当所有皇后成功放置(行号等于 $n$),将当前棋盘状态加入结果集。
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
#include <vector>
#include <string>
using namespace std;
class Solution {
public:
vector<vector<string>> solveNQueens(int n) {
vector<vector<string>> results;
vector<string> board(n, string(n, '.')); // 初始化棋盘
vector<bool> cols(n, false); // 列是否被占用
vector<bool> diag1(2 * n - 1, false); // 主对角线是否被占用
vector<bool> diag2(2 * n - 1, false); // 副对角线是否被占用
backtrack(0, n, board, cols, diag1, diag2, results);
return results;
}
private:
void backtrack(int row, int n, vector<string>& board,
vector<bool>& cols, vector<bool>& diag1, vector<bool>& diag2,
vector<vector<string>>& results) {
// 如果所有皇后都放置完成
if (row == n) {
results.push_back(board);
return;
}
for (int col = 0; col < n; ++col) {
if (cols[col] || diag1[row - col + n - 1] || diag2[row + col]) {
continue; // 如果当前列或对角线被占用,跳过
}
// 放置皇后
board[row][col] = 'Q';
cols[col] = diag1[row - col + n - 1] = diag2[row + col] = true;
// 递归处理下一行
backtrack(row + 1, n, board, cols, diag1, diag2, results);
// 撤销放置
board[row][col] = '.';
cols[col] = diag1[row - col + n - 1] = diag2[row + col] = false;
}
}
};
复杂度分析
- 时间复杂度:
- 回溯树的深度为 $n$,每层最多尝试 $n$ 个位置。
- 总的时间复杂度约为 $O(n!)$。
- 空间复杂度:
- 存储棋盘的空间复杂度为 $O(n^2)$。
- 递归栈的深度为 $O(n)$。
- 使用的辅助数组(列、主对角线、副对角线)总大小为 $O(n)$。
- 总空间复杂度为 $O(n^2)$。
示例运行
输入:
1
2
3
int n = 4;
Solution sol;
vector<vector<string>> results = sol.solveNQueens(n);
输出:
1
2
3
4
// results == [
// [".Q..", "...Q", "Q...", "..Q."],
// ["..Q.", "Q...", "...Q", ".Q.."]
// ]
优化与扩展
- 位运算优化:
- 使用位运算代替数组存储列和对角线状态,可以大幅减少空间占用并加快状态更新速度。
- 变种问题:
- 求所有解的个数(只需返回结果集大小)。
- 输出其中一种解。
总结
- 本题的核心在于通过回溯逐步尝试放置皇后,同时使用辅助数组快速判断合法性。
- 对于 $n \leq 9$ 的情况,回溯法的性能足够高效,结合位运算可处理更大规模问题。